A study from AI lab Anthropic shows how simple natural-language instructions can steer large language models to produce less toxic content.

Anthropic - Research Scientist, Societal Impacts

edX LLM Application through Production - ihower's Notes
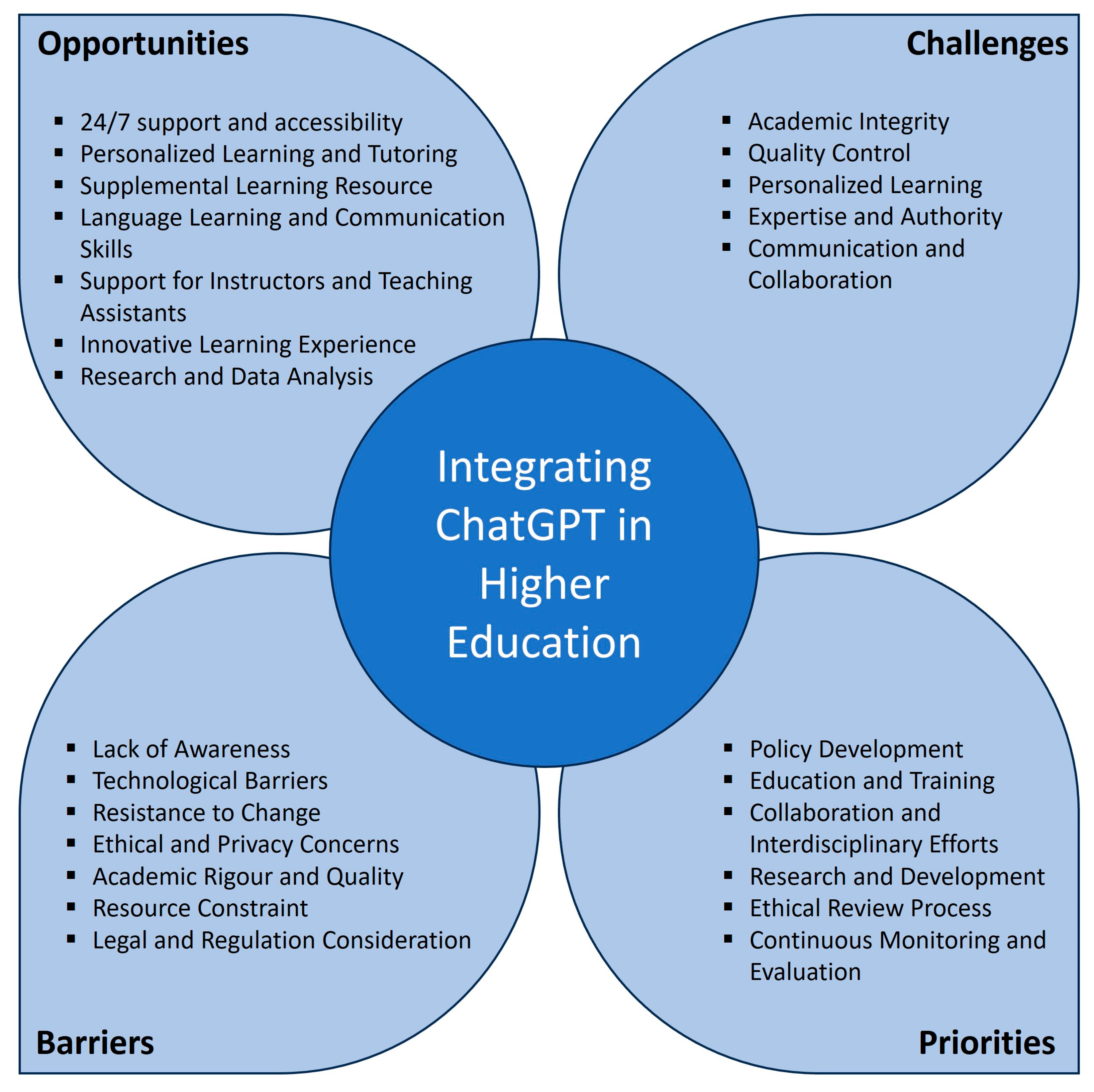
Education Sciences, Free Full-Text

Language models might be able to self-correct biases—if you ask

Anthropic - Research Scientist, Societal Impacts

Articles by Tate Ryan-Mosley

Philosophers on Next-Generation Large Language Models - Daily Nous

Scientific method - Wikipedia

language-models/llm-23.md at master · gopala-kr/language-models
Understanding Bias and Fairness in AI Systems, by Mary Reagan PhD

Large Language Models Will Define Artificial Intelligence

Harm Ellens on LinkedIn: Assessing Political Bias in Language Models

Articles by Clive Thompson