
Reinforcement Learning should be better seen as a “fine-tuning” paradigm that can add capabilities to general-purpose foundation models, rather than a paradigm that can bootstrap intelligence from scratch.

Prompt-based Learning Paradigm in NLP - Part 1

How Reinforcement Learning from AI Feedback works
Fine-Tuning LLMs with Direct Preference Optimization
D] Reinforcement Learning As A Fine-Tuning Paradigm : r/MachineLearning

Reinforcement Learning Pretraining for Reinforcement Learning Finetuning

Reinforcement Learning for tuning language models ( how to train
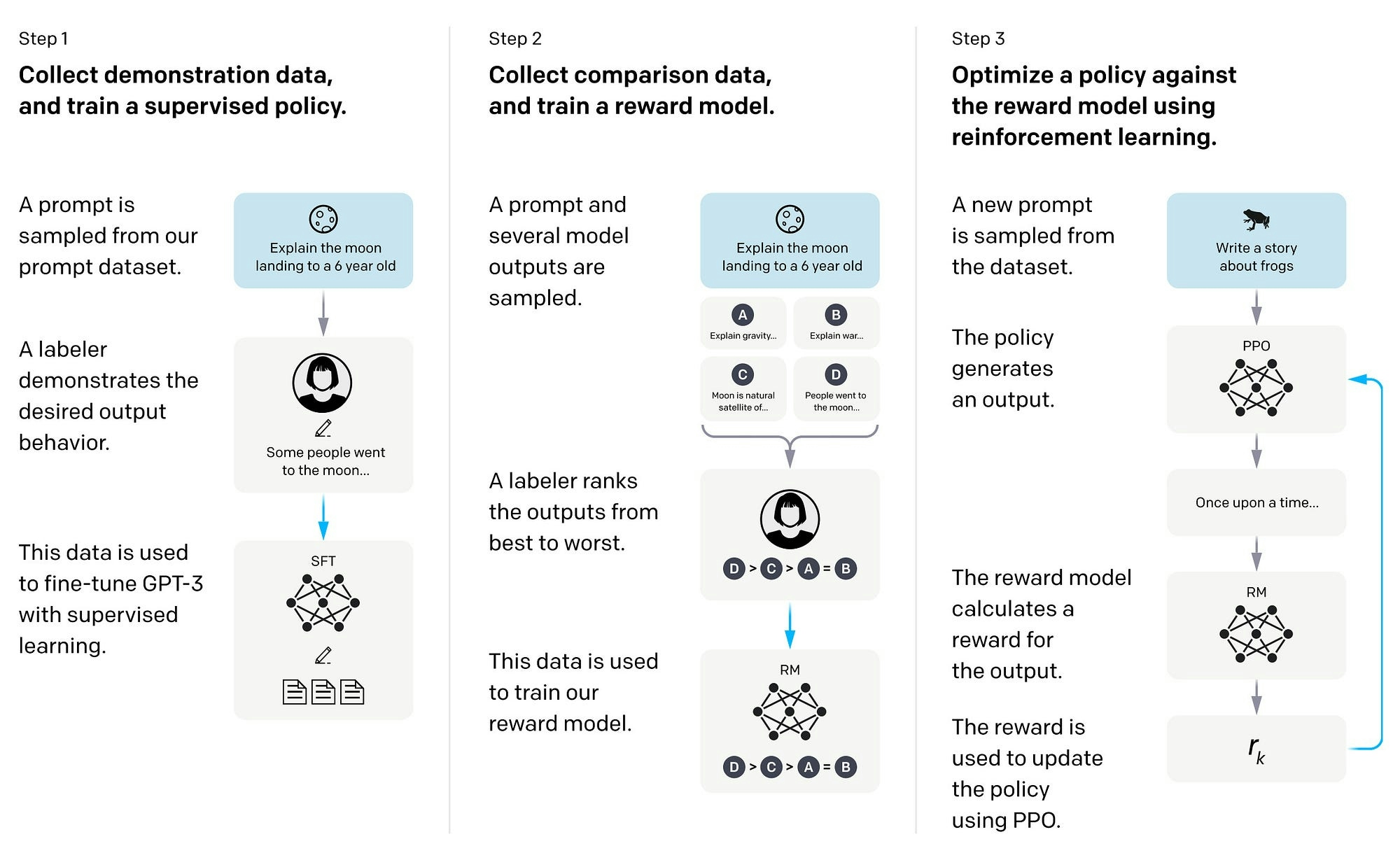
What is supervised fine-tuning? — Klu

Deep reinforcement learning for engineering design through
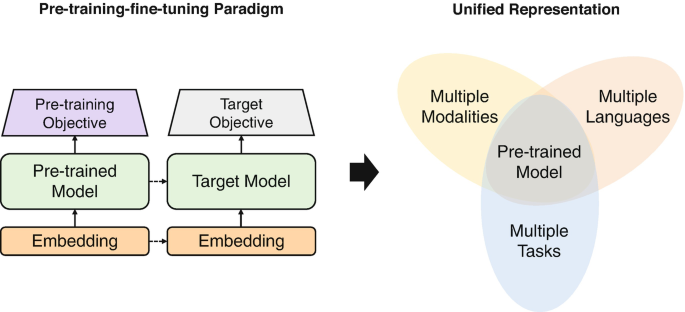
Pre-trained Models for Representation Learning

How are reinforcement learning and deep learning algorithms used

Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
Reinforcement Learning as a fine-tuning paradigm
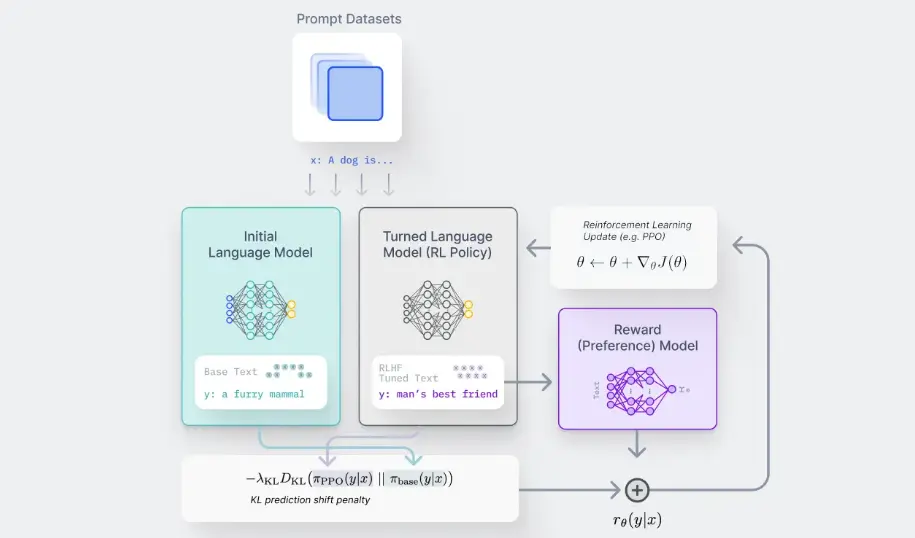
Complete Guide On Fine-Tuning LLMs using RLHF

The uneasy relationship between deep learning and (classical
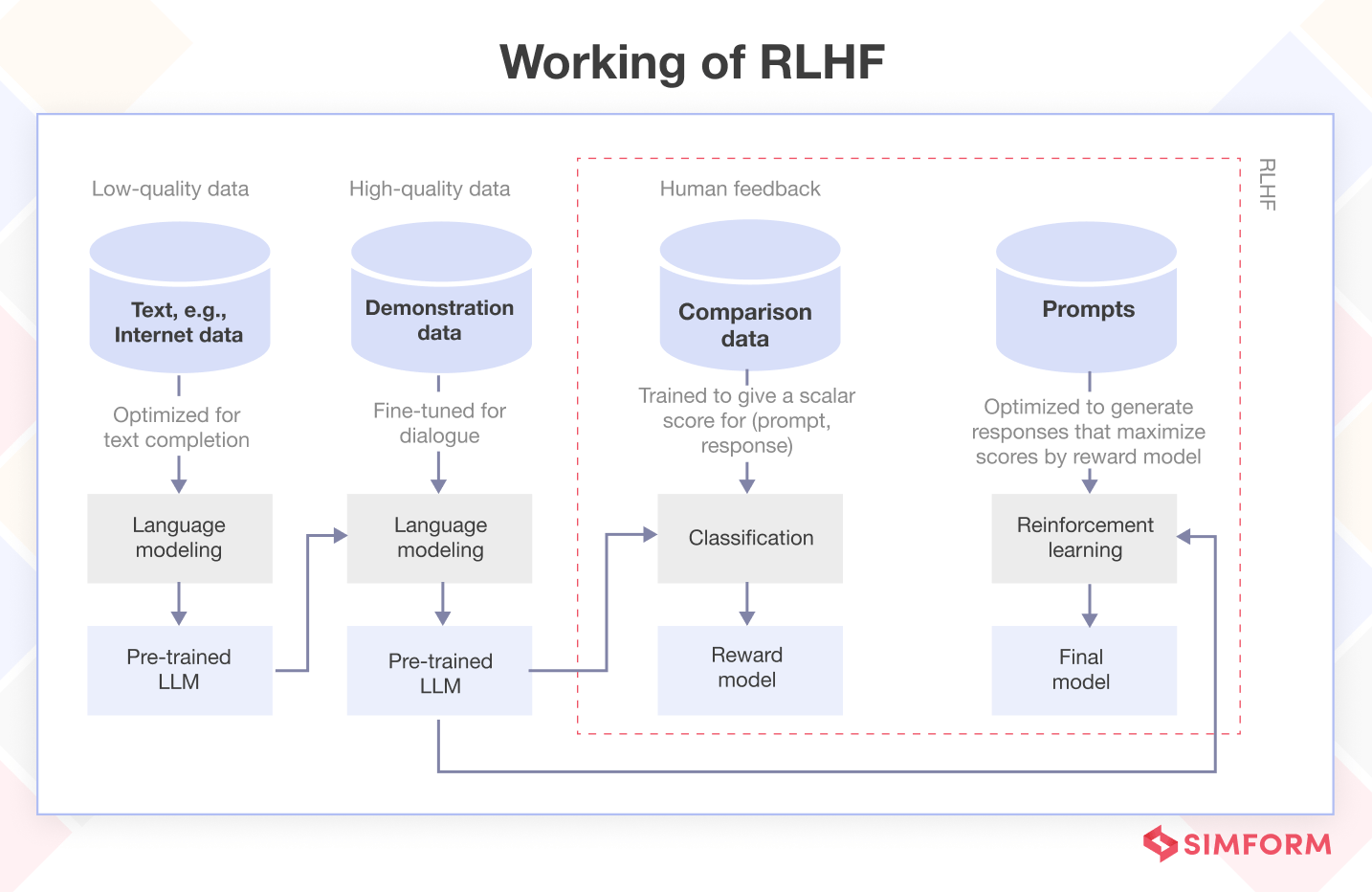
What is Reinforcement Learning from Human Feedback (RLHF)?


.png?width=1440&name=WHisper%20header%20(1).png)


