DeepSpeed Compression: A composable library for extreme

Large-scale models are revolutionizing deep learning and AI research, driving major improvements in language understanding, generating creative texts, multi-lingual translation and many more. But despite their remarkable capabilities, the models’ large size creates latency and cost constraints that hinder the deployment of applications on top of them. In particular, increased inference time and memory consumption […]
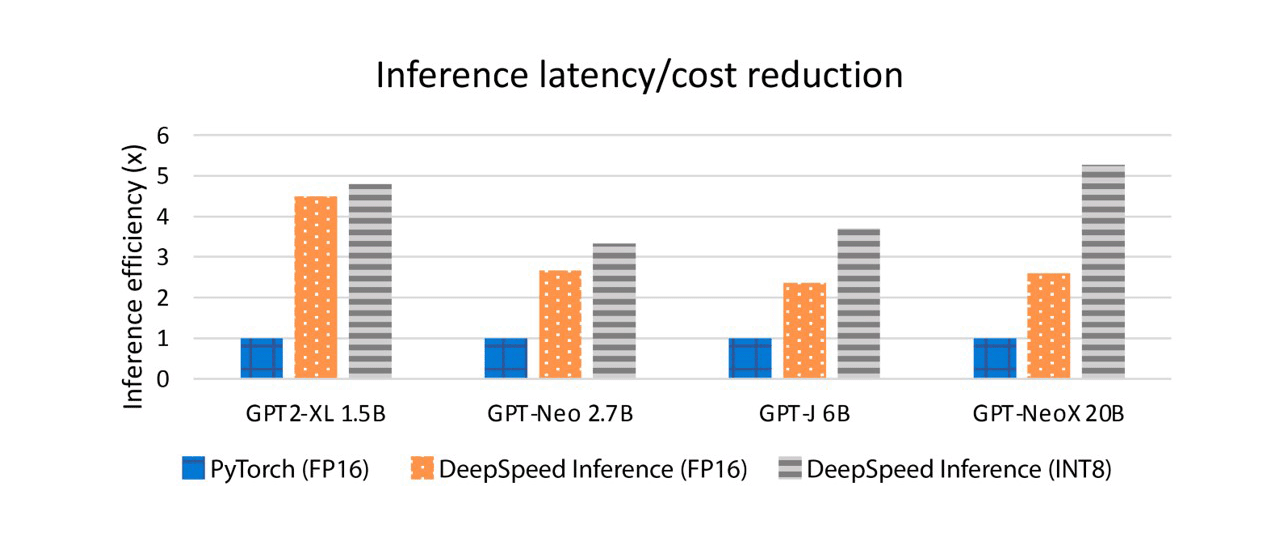
DeepSpeed Compression: A composable library for extreme compression and zero-cost quantization - Microsoft Research

Optimization approaches for Transformers [Part 2]

ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters - Microsoft Research
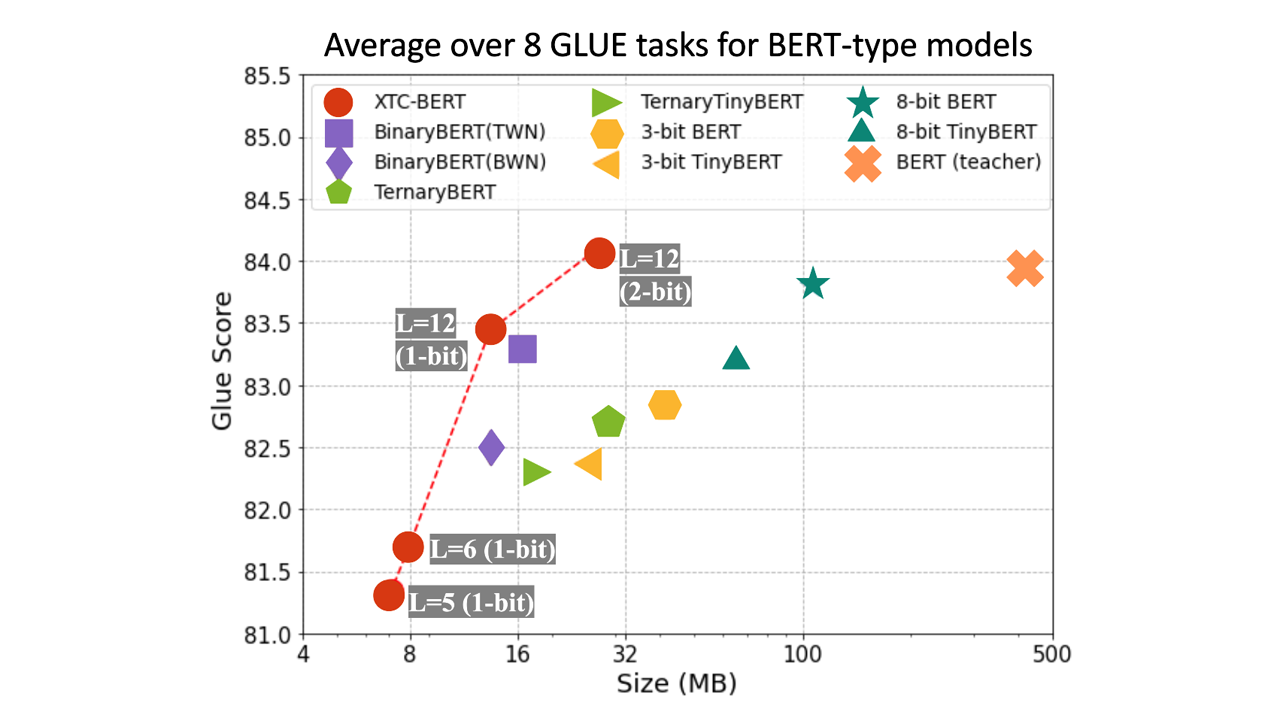
DeepSpeed Compression: A composable library for extreme compression and zero-cost quantization - Microsoft Research
如何评价微软开源的分布式训练框架deepspeed? - 知乎
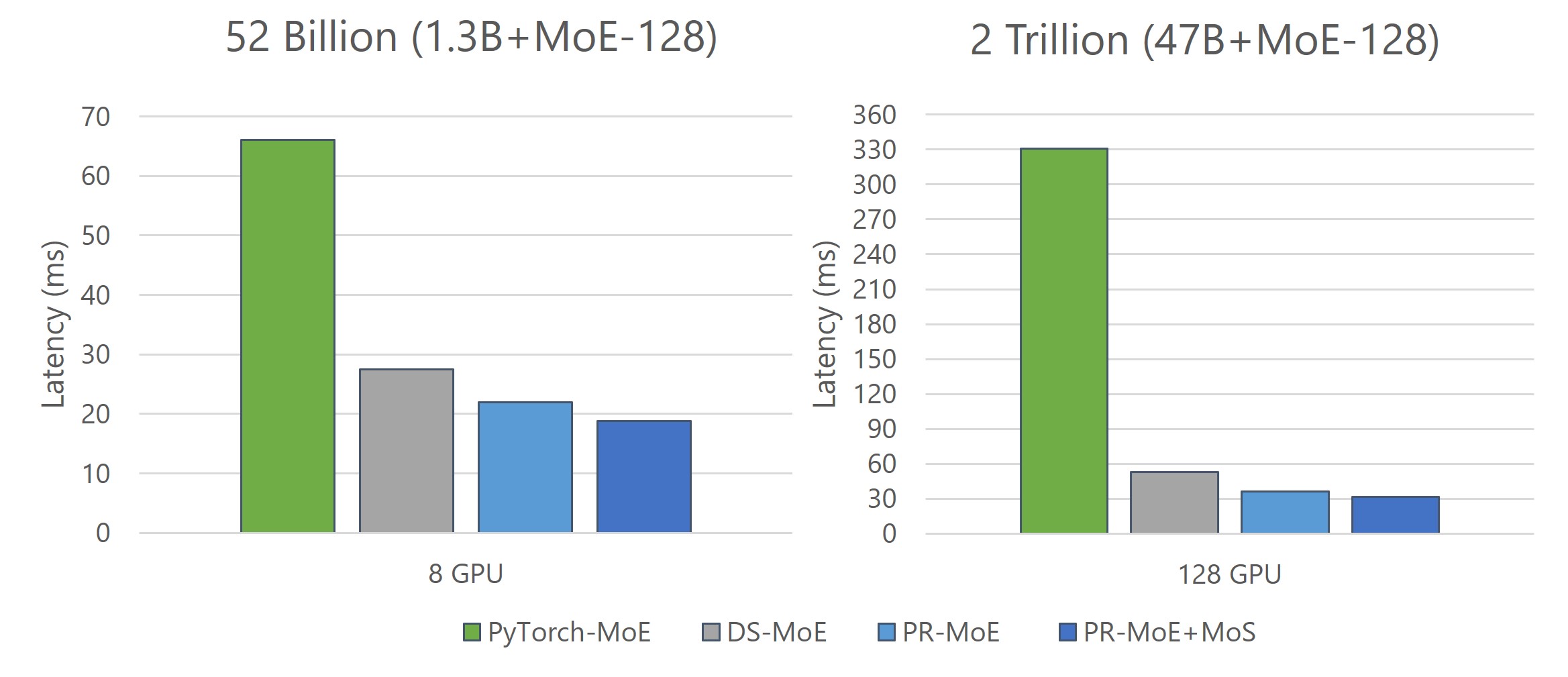
DeepSpeed: Advancing MoE inference and training to power next-generation AI scale - Microsoft Research

🗜🗜Edge#226: DeepSpeed Compression, a new library for extreme compression of deep learning models

Shaden Smith on LinkedIn: DeepSpeed-MoE for NLG: Reducing the training cost of language models by 5…

GitHub - microsoft/DeepSpeed: DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective.
ChatGPT只是前菜,2023要来更大的! - 墨天轮
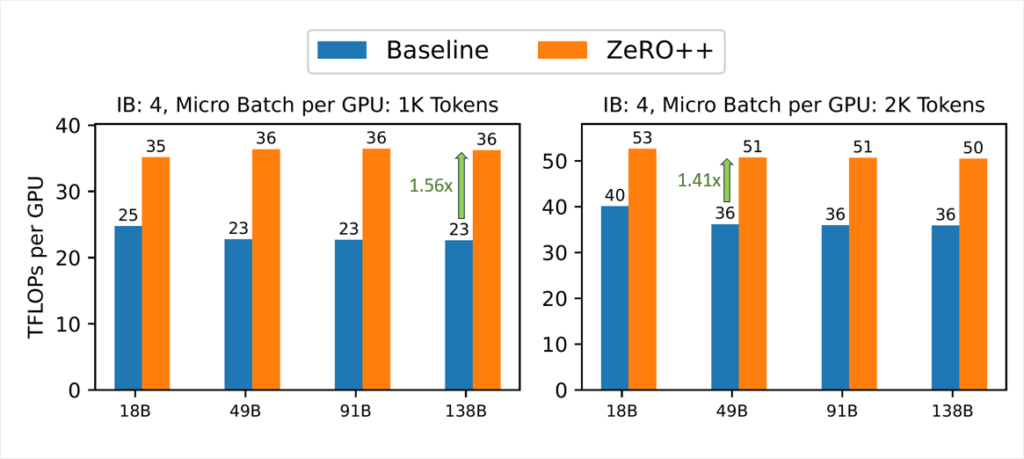
DeepSpeed ZeRO++: A leap in speed for LLM and chat model training with 4X less communication - Microsoft Research

Gioele Crispo on LinkedIn: Discover ChatGPT by asking it: Advantages, Disadvantages and Secrets

Xiaoxia(Shirley) Wu (@XiaoxiaWShirley) / X

Memory Management on Modern GPU Architectures







